13
May
11:00
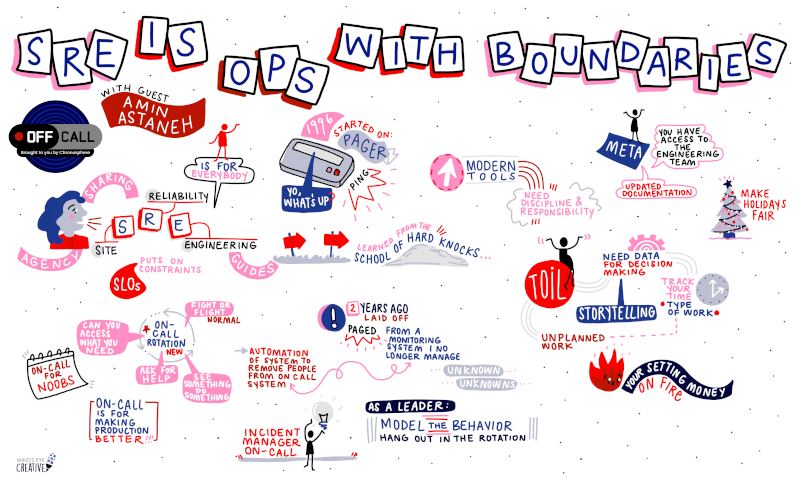
Something has been frustrating me about “SRE” for a long time.
It seems that SRE as a job title has been diluted to little more than on-call support, undoing years of lessons learned by the tech industry around mature production operations.
It feels like every week, someone posts to r/SRE with their frustrations, only to discover that their job isn’t SRE at all, despite their title. I sometimes comment to provide some guidance and support,...