

In our Incident Management series, we’ve talked about how mature monitoring, escalation policies, and alerting enable a swift response when things go wrong in production. Let’s now talk about the people and processes that actually do the responding: the on-call rotation.
Simply put, an on-call rotation is a group of people that share the responsibility of being available to respond to emergencies on short notice, typically on a 24/7 basis. This practice is common to industries like medicine and emergency services in addition to software engineering and IT operations.
In our context, the on-call rotation is the recipient of the alerts or escalations we’ve previously described. In this article, we’ll go over recommendations and best practices when setting up and running an effective on-call rotation.
Sufficiently Staff the Rotation
According to the original SRE practices:
“Oncall teams should have at least 8 people at one location, or 6 people at each of multiple locations.”
I agree with this guidance: assuming an on-call shift lasts one week, an engineer would be on-call every 6-8 weeks. That frequency is often enough for them to remain in touch with the operational realities of production, without applying undue stress or burden.
Remember that on-call is disruptive; the engineer is tied to their phone and laptop, and noisy alerts will make them irritable and sleep deprived. I have seen teams try to get by with as little as three engineers which invariably leads to disaster due to burnout or attrition.
Don’t Delegate On-Call To Another Team
In the classic Dev vs Ops model, the software engineering team hands total operational responsibility (including on-call) to the operations team. This is a problematic and ill-advised practice in most cases and has been labeled as such for over a decade.

The reason goes back to the Second Way of DevOps: Feedback. The on-call team does not have the intimate knowledge of how the service is developed nor do they have the ability to truly address production issues. They will escalate to the engineering team anyway, which takes additional time and will increase MTTR.
By having the engineering team be on-call, the feedback loop is tight. Alerts are being routed to the team best equipped to respond to problems. They will be automatically incentivized to address on-call pain as it blocks them from delivering feature work.
Charity Majors, CEO of Honeycomb, says it best:
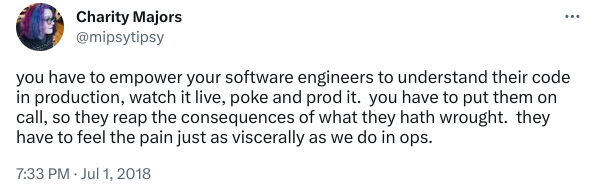
Everyone On the Team Should Be On-Call
In a previous SRE engagement I led as an individual contributor, I discovered while onboarding to the team that only ⅓ of the engineers were in the on-call rotation!
Their reasoning was that the team was so large, that if all of them were on-call, they wouldn’t experience it often enough in order to be effective. The consequence was that most of the team was completely unaware of the current state of production and therefore had limited empathy for the members of the on-call rotation (and their customers!).
The solution was to split the scope of on-call responsibilities into two (customer support and backend infrastructure) and create two rotations, which allowed for all members of the team to be on-call. Naturally, the effect was that the engineering team collectively began to care more about reliability.
No Project Work During the On-Call Shift
Place ZERO expectations on the on-call to do project work during their shift.
(If you use Scrum: ensure that their capacity is NOT counted during sprint planning during that period.)
Their effort needs to be 100% focused on the reliability of the system.
If they aren’t responding to an alert, they should be looking at support requests. If there are no support requests, they should be working on improvements or follow-up tasks from previous incidents. (Your team has tracked that work in a ticketing system, right?)
Set Expectations for Time-To-Keyboard
‘Time-to-Keyboard’ is how long it takes for an on-call to receive an alert and then be able to triage and respond. This means being in front of their computer with a reliable internet connection.
Set clear expectations with the team on the expected timeframe. For most teams, 10-15m is acceptable. For services with higher reliability requirements, a ‘follow-the-sun’ rotation across multiple geographical regions may be necessary.
Check For Working Tools and Production Access
When an engineer starts a new on-call shift, make sure that they verify that all of the prerequisites required for swift and effective incident response are in place. Examples:
- Their phone should still vibrate and make noise when paged, even when set to ‘do not disturb’.
- They should have access to observability tools, runbooks, a recent code checkout, and production credentials (if necessary).
Do On-Call Handoffs and Retrospectives
At the conclusion of each shift, the previous and current on-call should have a meeting where they discuss outstanding work or incidents so that nothing falls through the cracks.
Some teams even explicitly do the handoff to ensure there is constant custody over the pager. At a previous job, I wrote a chatbot plugin for this exact purpose.
In addition to the handoff, I recommend inviting the entire team to join and perform a full-on retrospective where gaps and improvements to on-call tooling and process can be identified and tracked. The retro can be short (15 min), or even be part of a weekly postmortem review.
Use Effective Tools for On-Call Management
How do you ensure alerts get routed to the on-call? Very early in my career, on-call shifts were scheduled in Google Calendar, and our monitoring system sent alerts to a set of custom email accounts belonging to everyone in the rotation. When an engineer started their shift, they simply enabled sync and notifications for their email account on their cell phone. Of course, this process was very error-prone.
These days there are SaaS products available that allow for the creation of on-call rotations, performing schedule changes and overrides, ingesting and routing notifications from monitoring systems, and configuring push notifications, chat messages, texts, and phone calls for alerts.
Pagerduty has been the tried-and-true option over the years. There are however many alternatives that handle full-on incident management, rather than just alerting.
Report on On-Call Metrics
Track and dashboard the following metrics at minimum for your on-call rotation:
- Number of alerts per shift
- Number of support requests per shift
Share the shift-to-shift metrics on a periodic basis with your team preferably as part of the on-call retrospective, and investigate causes for any increase.
This information allows you to set goals toward the reduction of the amount of work the on-call shift absorbs, thus keeping it sustainable.
Conclusion
On-call is necessary for appropriate and timely response to emergencies in production. The software engineering team is best equipped for this responsibility as they have the knowledge to remediate problems and need to understand the impact of their changes on system health. There are ways to manage that process that is both effective and humane for the team.
Need help implementing these best practices for your team? Reach out to schedule an introduction!
(Image Credit: Sora Shimazaki)