25
Feb
18:00
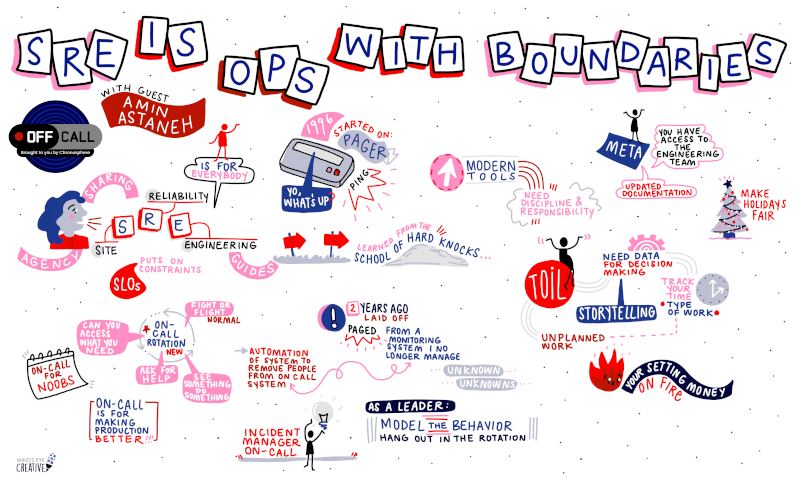
I sat down with Better Stack’s podcast to discuss the AI velocity -> operational chaos thesis, my time at Meta, my SRE career in general, and a few tales from my life on the road!
Thanks Better Stack for an action-packed conversation!